AI-generated code will choke delivery pipelines
Everyone is focused on the impact of AI on the production of code. But code isn’t just produced, it has to be consumed: built, packaged, tested, distributed, deployed, operated. Leveraging AI to amplify the supply of code will grow already complex systems and accelerate the pace of change. Without a realistic plan to scale delivery pipelines, we’re asking for trouble.
There is already smoke on the horizon. The DORA report on Generative AI impact in Software Development released March 2025 notes how “contrary to our expectations, […] AI adoption is negatively impacting software delivery performance.”
After all, the software industry was already competent at increasing supply well before AI. The real struggle happened on the systems downstream. Here is Slack in 2022:
For several years, internal tooling and services struggled to keep up with 10% month-over-month growth in CI/CD requests from a combination of growth in 1) internal headcount and 2) complexity of services and testing. Development across Slack slowed.
Saturated delivery pipelines aren’t just a technical headache. They rate limit businesses when growing the flow of changes is most important. But scaling delivery pipelines the way we’re used to won’t work against a flood of AI-generated code.
Software delivery is a trap of compounding complexity
The default approach to software delivery is defensive, with emphasis on capturing defects before they reach production.
That turns every growth cycle into a storm of compound effects. More code leads to larger, more complex systems that are exponentially harder to test and operate. And change has the annoying side effect of breaking things, so optimizing to produce more code also means optimizing for more breakage. Work accumulates, and doing it keeps getting harder.
It is no coincidence that Slack’s growth pains concentrated around testing. “At its worst, our time-to-test-results for a commit was 95 minutes”, “test flakiness per pull request consistently around 50%, “cascading failures on overloaded delivery infrastructure”, and so on.
Those are familiar growth pains along the narrative arc that starts with a couple of Jenkins jobs, and ends with a proliferation of broad, heavy weight test suites, a hydra of dev / test / staging environments, the inevitable Rube-Goldberg mechanism (a.k.a., “internal platform”) to manage the whole mess (provision and maintain infrastructure, keep test data, component versions, and configuration coherent and aligned with each other and production). All with the obligation to keep production-grade SLOs because any malfunction in the delivery pipeline has the potential to paralyse the business.
If compound effects bring trouble, how could people get away with defensive delivery?
Because growth has natural constraints. Hiring budgets dry, org charts get too heavy: growth stops. At that point technical infrastructure gets a chance to breathe, catch up with the flows of code and reach a stable equilibrium. Some friction remains, but the speed bumps are tolerable (Slack was content with reaching “test turnaround time (p95) […] consistently below 18 minutes and significantly more predictable””.)
AI melted the growth constraints that protected delivery pipelines
To an organization that needs to produce more software, hiring budget or management overhead are a smaller obstacle once $20 copilots are enough to power-up the existing headcount.
But AI does a lot more than make engineers churn more code. It expands the population that can produce it. It shifts tactical trade-offs in ways that favour creating more code (e.g. when cloning functionality is cheap, the incentive to reuse dissolves). When AI is able to deliver coding tasks based on a prompt, there won’t be enough copies of the Mythical Man Month to dissuade business folks from trying to accelerate road maps and product strategies by provisioning fleets of AI coding agents.
Will this translate into a net increase of actual value or just an accumulation of slop and technical debt? Regardless of the answer, there will be more raw code, making every organisation susceptible to growth pains of a much larger scale than they were used to.
Can’t we automate the problem away?
No. Automation will make the problem worse. It does help get more work done, but when the job is producing software, that translates into added pressure on delivery pipelines. To get a measure of the impact of automation on flows of code, consider these charts from a classic Google article in 2015, well before AI:
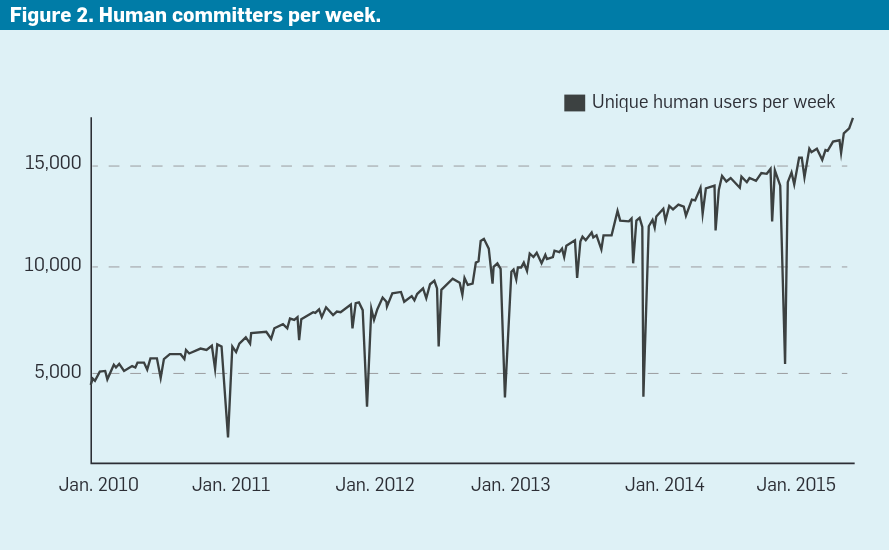
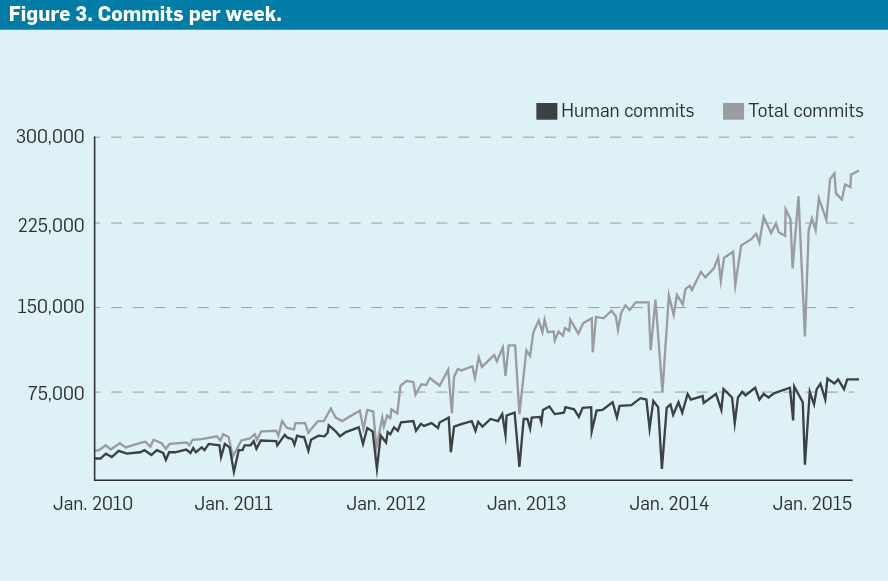
In 5 years, Google had ~3x as many human committers, and their commits grew by roughly the same amount. Meanwhile, the total commit rate multiplied by 10. It was because of automation: over 60% of all commits at Google came from tools like Rosie, used for “performing large-scale code changes” and responsible for ~7,000 commits per month. This isn’t exclusive to FAANGs: at Adevinta’s engineering platform, serving a few hundred engineers, our bots produced 7,500 commits per month during 2019, and that was just automating basic chores (e.g. internal dependency updates, configuration changes, etc.).
AI also boosts automation. Which gets more effective, and broadens its scope to more complex tasks like writing tests, infrastructure management, fixing easy bugs based on support tickets, etc. Capabilities that will keep expanding. This opens immense opportunities by making it viable to solve challenging, higher order problems. But that means code. A lot. Of. Code.
The old playbook to scale software delivery is obsolete
Scaling delivery pipelines traditionally boiled down to splitting the larger system into subdomains that enabled independent flows of code. This was one of the main selling points of modern architectures patterns like microservices, serverless, event driven, etc.
But this strategy is deceptive.
The final system is still one so all flows merge in it eventually, surfacing failures that only manifest when components interact together under real world conditions. An organization that insists on capturing issues before production starts hopping across a catalogue of poor quality filters:
- Allow independent flows all the way to production, exacerbating the complexity and cost of troubleshooting late integration issues in an environment that never stops changing.
- Sequence full-system tests and roll out to production with a monolithic delivery process. Which adds control, but defeats the point by slowing down the entire pipeline.
- Batch N changes in 1 “release” event to amortize time and cost, which lead to long-lived “rc” branches and stabilization periods, hold up new development, and have the same effect on troubleshooting (which of the N changes caused each issue?)
- Allow independent flows all the way to production after a full system validation stage. Which leads to the self-feeding Golem made of flake-prone, time-consuming, broad scope test suites, the environment replicas they run on, and the Rube-Goldberg apparatus to manage them.
The few organizations that went through sustained growth periods saw their pipelines overwhelmed. AI will democratize that experience.
Scaling software delivery by shifting focus from defense to offense
“How complex systems fail”, #4:
The complexity of these systems makes it impossible for them to run without multiple flaws being present. […] Eradication of all latent failures is limited primarily by economic cost but also because it is difficult before the fact to see how such failures might contribute to an accident.
It is impossible to predict every failure mode, let alone replicate it during development. So why obsess with it? Testing code ahead of production will always add value. But past an initial safety net, focus should be on building systems, tools, and processes that can absorb the fast rate of change that will become the norm as AI disseminates across the industry.
My rough mental playbook for scaling delivery pipelines in an AI-driven ecosystem:
- Reference defensive testing to a diminishing returns curve, and trim aggressively. Keep fast, low footprint tests for single components, without dependencies on other components or dedicated infrastructure. Verify both sides of API contracts. Replay actual production data rather than programming mocks. Ship.
- Minimize dev / test / staging and similar environments, ideally removing them completely. Shift relevant test suites to canary / smoke tests. Add synthetic load directly on production. Get code where the real action is, and learn to survive there.
- To measure and track quality, prefer metrics that look at business outcomes and user experience than properties of code. Product SLA / SLOs, error budgets, etc. work better than test coverage, static analysis, bug counts and QA reports (even if they have their utility.)
- Get comfortable with operating high-entropy environments with high rate of change. Design systems that expect failure but minimize impact. Provide high-cardinality, context-rich observability that speeds up detection diagnosis and resolution.
- Expect to accommodate radical changes in testing practices as production systems start incorporating inference workloads, making non-deterministic test results a feature rather than an anomaly. Even worse if the product embeds ML pipelines with continuous workflows of (re)training, selection, deployment of models, requiring additional infrastructure, data intensive workflows, etc.
- Treat security as an additional dimension of failure, rather than a sporadic event to worry about during quarterly audits. Probe for holes, in production, continuously.
- De-emphasize practices based on control and coordination.
- A prominent example are code reviews. They did deliver valuable outcomes, but at the expense of throttling delivery. The landscape has changed now. Humans are not the only inhabitants of codebases. Sustaining a high rate of changes is more critical. Software maintenance economics are upside down. We can’t do code reviews like the 10 years ago.
- Another: API contracts should be able to evolve without coordinating systems on each side. Normalize having N versions of an API alive in production at any point in time, with self-directed strategies to measure usage, deprecation, migrations, etc.
- In some critical systems, a slower, more defensive approach is non negotiable (e.g. health care, aviation, etc.). Using AI to augmenting the supply of code may not be adequate.
- …
I will close with a quote from Charity Majors: “we need to help each other get over our fear and paranoia around production systems. You should be up to your elbows in prod every single day. Prod is where your users live. Prod is where users interact with your code on your infrastructure.”
This was already true when humans were the only ones. We have to make room for the AIs.
More writing
- DDoSing Software Delivery Pipelines Jun 2026
- Inferencing delivery bottlenecks away Mar 2026
- Code reviews can't keep up Feb 2026
- AI workloads challenge the cattle model Feb 2026
- PoC is a framework of perverse incentives Jan 2026
- Why aren't we all serverless yet? Jan 2025
- See all →