Migrating an Eureka-based microservice fleet to Kubernetes
I have published some articles recently related to the Kubernetes-based PaaS that my team builds for the engineers behind the online marketplaces of Adevinta. Some concerned low level issues that we found as we brought teams in to the platform, like dealing with OOM kills with JVM apps or understanding why one service suddenly exhibited 10x latency after deploying it in Kubernetes.
The last one was more high level, focusing on our vision and strategy. I spoke there about how a lot of the value we provide in the glue between systems. This article will go in depth into one of those bits of glue. I will talk first about motivation, our architectural decisions, outcomes, and future plans. At the end there is a deeper dive in the implementation and testing strategy for that bit of glue.
If you want to receive notifications for new posts, subscribe to the RSS feed or follow me on Twitter.
Context and goals
We are currently busy migrating a large fleet of microservices from one tenant into our PaaS. This tenant covers Adevinta’s online marketplaces in Spain (MilAnuncios, Infojobs, Fotocasa, Habitaclia, and others.) Most of these share a microservice platform based on EC2 that leverages tools in the NetflixOSS stack. A key component is Eureka, which provides service discovery and underpins client-side load balancing.
Kubernetes is able to deal with both service discovery and load balancing on its own, although using very different approaches. This change works for us in the grand scheme of things, but I here won’t discuss client vs. server-side load balancing (you can read about them here or here). Migrating to Kubernetes does enable us to eliminate moving pieces from the legacy infrastructure: we can remove Eureka, microservices can drop the corresponding integration, and forget about load balancing.
But performing a migration from EC2 to Kubernetes while introducing major architecture changes is not a good idea for reasons that are, I hope, obvious enough to omit. We know from the beginning of the project that the migration would happen gradually, avoiding any change that is not strictly necessary for our goal in order to minimize risk and impact on product teams. Any product engineer should be able to migrate a microservice in 1-2h and get on with their work.
That means for the duration of the project (months) we’ll have services fully deployed on the legacy EC2 infrastructure, others only in Kubernetes, others inbetween worlds. We had to figure out a way to make the differences in environments transparent until we are ready to deprecate the old infrastructure of this tenant.
For our Platform team, there is a second goal: bring teams from Adevinta Spain into the fold of our Golden Path, together with other Adevinta Marketplaces. Reducing software sprawl means that Platform teams use economies of scale to provide more value for the business.
Understanding our legacy architecture
The legacy microservice platform is deployed in a handful of AWS accounts following a fairly standard architecture. Here is a (very) simplified view of one account:
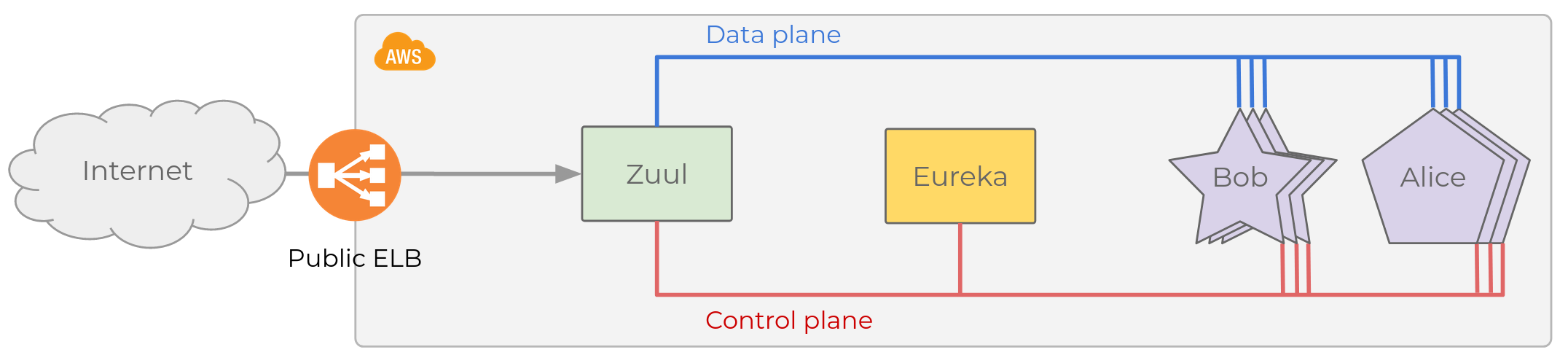 Eureka architecture (source)
Eureka architecture (source)
There are about 200 services, all communicate with HTTP. In the diagram
I show two, Bob and Alice represented with stars and pentagons, 3
replicas each. Microservices talk to each other and may serve requests
coming from the Internet.
Internet traffic reaches backends through a single API Gateway that is
shared by all AWS accounts. We use
Zuul, an L7 gateway that can
handle TLS termination, header manipulation, dynamic routing, etc. It is
configured to map names such as bob.spain.adevinta.com to a given
backend service, find an instance, and proxy traffic to it.
But which replica? Zuul and all microservices decide based on the information maintained in a service registry, Netflix Eureka. All instances in the network (both microservices and Zuul) interact with the service registry in two ways:
- They register their service name, IP, port, health endpoint, and other metadata to Eureka as soon as they come up, and keep refreshing the same information with regular heartbeats as long while they are available. When heartbeats stop, Eureka evicts the instance from the registry after a timeout.
- They poll Eureka to learn the set of available instances for each service and implement richer logic on top (load balancing policies, retries, etc.) We rely on Netflix Ribbon for this.
Let’s see an example. Given the diagram above, Eureka’s registry would look something like this:
| Service | Instance ID | Endpoint | Port | … |
| Bob | Bob1 | 168.1.1.21 | 80 | … |
| Bob2 | 168.1.1.22 | 80 | … | |
| Bob3 | 168.1.1.23 | 80 | … | |
| Alice | Alice1 | 168.1.2.31 | 80 | … |
| Alice2 | 168.1.2.32 | 80 | … | |
| Alice3 | 168.1.2.33 | 80 | … |
When someone wants to send a request to Bob, it would do something
like this:
ribbon.sendRequest("http://bob/hello", ..)
Behind the scenes, Ribbon would look up which instances are associated
to service bob, choose an instance and send the request
there.
We can then distinguish two channels of communication.
- The Data Plane (blue), used to exchange application data.
- The Control Plane (red), used to exchange information that determines how traffic will flow through the Data Plane (e.g. which instances can receive traffic.) Eureka is the core component of the Control Plane in the legacy infrastructure.
Data and control plane may actually use the same networks, but are fundamentally different concerns.
Understanding the target architecture in Kubernetes
To deploy microservices like Bob and Alice we use ordinary
Deployment
objects that generate a number of
Pods running
the microservice. For each Deployment we also create a
Service
that defines how to reach those Pods. This is how Kubernetes wires
things up:
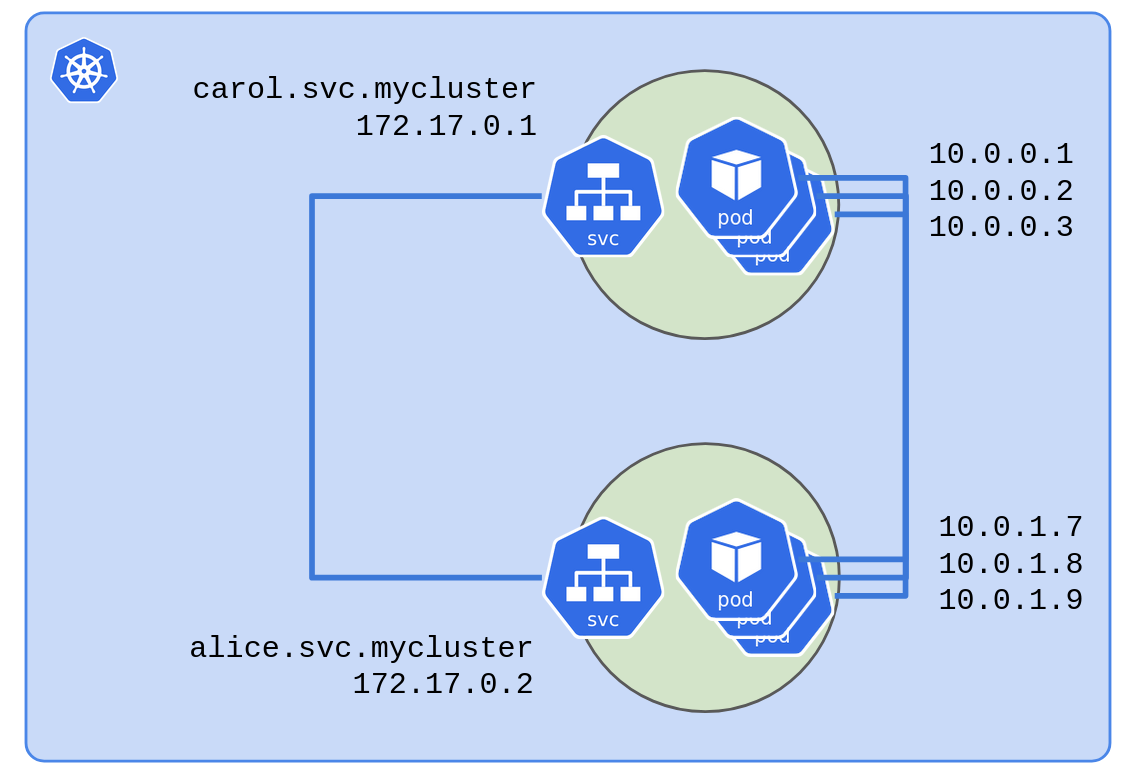 How we deploy a microservice in Kubernetes
How we deploy a microservice in Kubernetes
Each Service object gets a private DNS record like carol.svc.mycluster
that resolves to a virtual IP (172.17.0.1 in the diagram). When any
Pod talks to carol.svc.mycluster Kubernetes will do its
magic
and route traffic to healthy Pods running Carol.
But this is problematic for us. Our Kubernetes cluster runs on its own
AWS account (not EKS, for $reasons.) We use VPC
peerings
to link a private subnet in that AWS account, to in each of the AWS
accounts of the legacy environments. This gives connectivity, but only
up to the Kubernetes underlay network, that is, to the Kubernetes
nodes. Not to any of the resources in the overlay network like
Pods or Services.
Let’s see the diagram updated with a VPC peering between both AWS accounts.
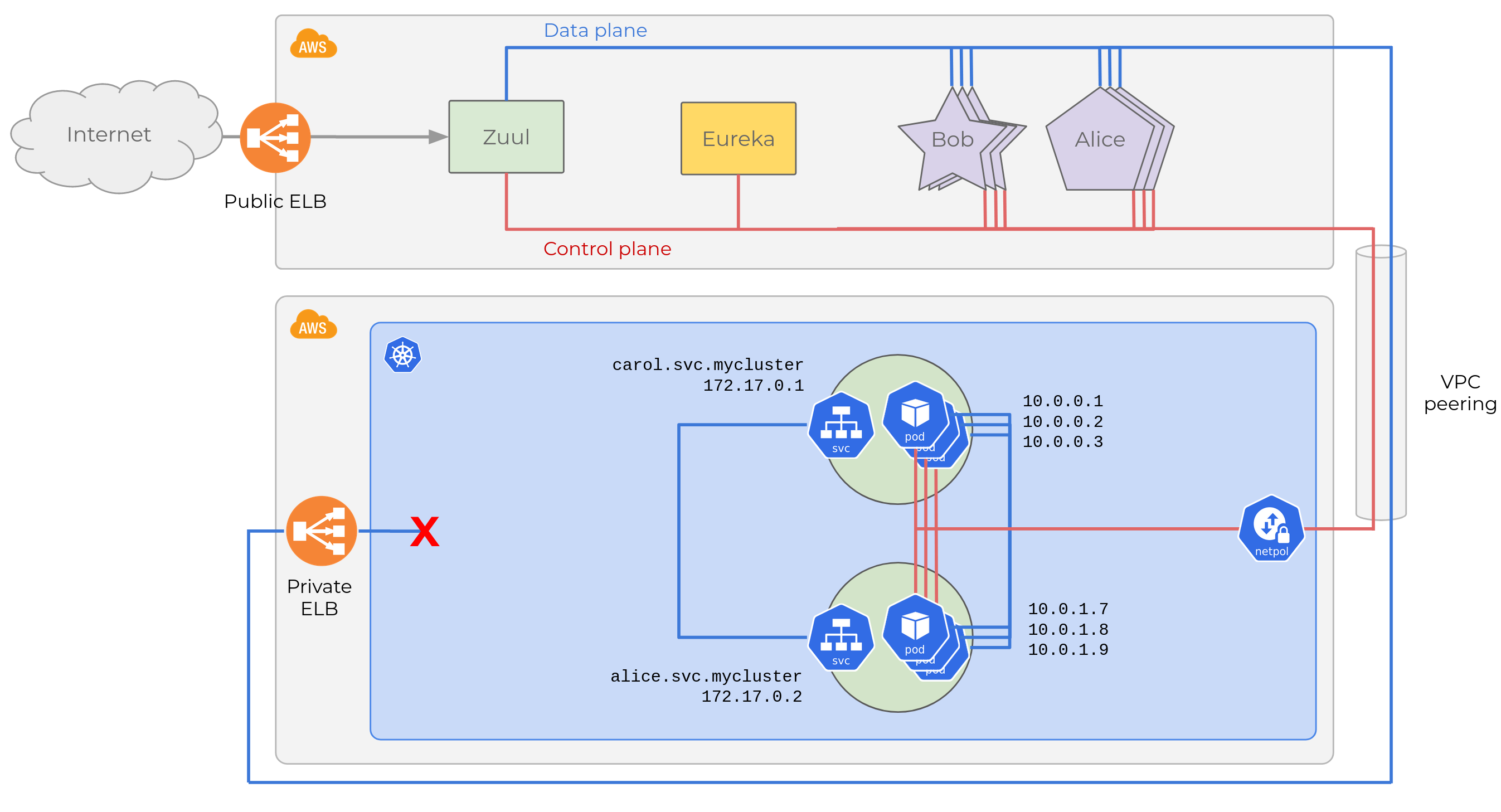 Our starting point: legacy and new infrastructures
Our starting point: legacy and new infrastructures
When our Pods come up, they will be able to register in Eureka (we
also configured network
policies
to allow traffic from Kubernetes to AWS accounts). But they will report
their container’s IP on the overlay network, which is private to
Kubernetes. Eureka’s registry will contain the following entries:
| Service | Instance ID | Endpoint | Port | … |
| Bob | Bob1 | 168.1.1.21 | 80 | … |
| Bob2 | 168.1.1.22 | 80 | … | |
| Bob3 | 168.1.1.23 | 80 | … | |
| Alice | Alice1 | 168.1.2.31 | 80 | … |
| Alice2 | 168.1.2.32 | 80 | … | |
| Alice3 | 168.1.2.33 | 80 | … | |
| Alice-k8s-1 | 10.0.1.7 | 80 | … | |
| Alice-k8s-2 | 10.0.1.8 | 80 | … | |
| Alice-k8s-3 | 10.0.1.9 | 80 | … | |
| Carol | Carol-k8s-1 | 10.0.0.1 | 80 | … |
| Carol-k8s-2 | 10.0.0.2 | 80 | … | |
| Carol-k8s-3 | 10.0.0.3 | 80 | … |
All 10.0.*.* IPs are inaccessible from the legacy environment, so this
will be an utter mess. All requests from Bob (only deployed in EC2)
to Carol (only in Kubernetes) will fail. Half of Bob’s requests to
Alice will also fail. Ribbon will be clever enough to blacklist
unreachable instances from the local caches of the service registry in
each microservice, but other cases will be completely broken. For
example, half of Alice’s instances in EC2 won’t be able to reach
Carol. And Carol might be able to send requests to Bob and
Alice just depending on how network policies are configured.
This is clearly not what we want.
Fixing the control plane
Our problem is that the control plane is broken. Instances of our microservices that run in Kubernetes feed the service registry with data that induce bad decisions about where application traffic should be addressed (e.g. sending requests to unreachable IPs.)
There are some options to fix this. One is to adapt the Data Plane, wiring both networks so that the Kubernetes overlay belongs in the private subnet of the cluster’s AWS account. This, combined with the VPC peerings, means that we can route to/from the tenant’s AWS account. This option would work well with EKS.
We chose a different approach for various reasons. The main one relates to the fact that we maintain several multi tenant clusters. Tailoring their architecture to each tenant’s infrastructure quirks is a slippery slope which inflates our operational burden and has bitten us hard in the past. Instead, we prefer to keep our Kubernetes infrastructure as standard as possible, and treat our clusters as cattle.
The approach we followed has two parts:
- Exposing the
Serviceobjects outside the cluster through standard Kubernetes constructs. - Joining the Kubernetes Control Plane to the legacy Control Plane.
Exposing Service objects outside the cluster
Kubernetes offers three well defined mechanisms for this. The two most
basic
ones.
are NodePort and LoadBalancer, which cover up to L4 (TCP/UDP). For
higher level functionality (TLS termination, HTTP path based routing,
etc.) you can use an Ingress
Controller.
This is the standard in our platform.
When we have a Service that needs to be exposed outside the cluster,
we create an Ingress for it, with a standard host name
(<service_name>.k8s.adevinta.com). The Ingress Controller (NGINX in
our case) will handle requests to external endpoints, and route them to
a Service. Here is the diagram updated after adding two Ingress
objects for Alice and Carol.
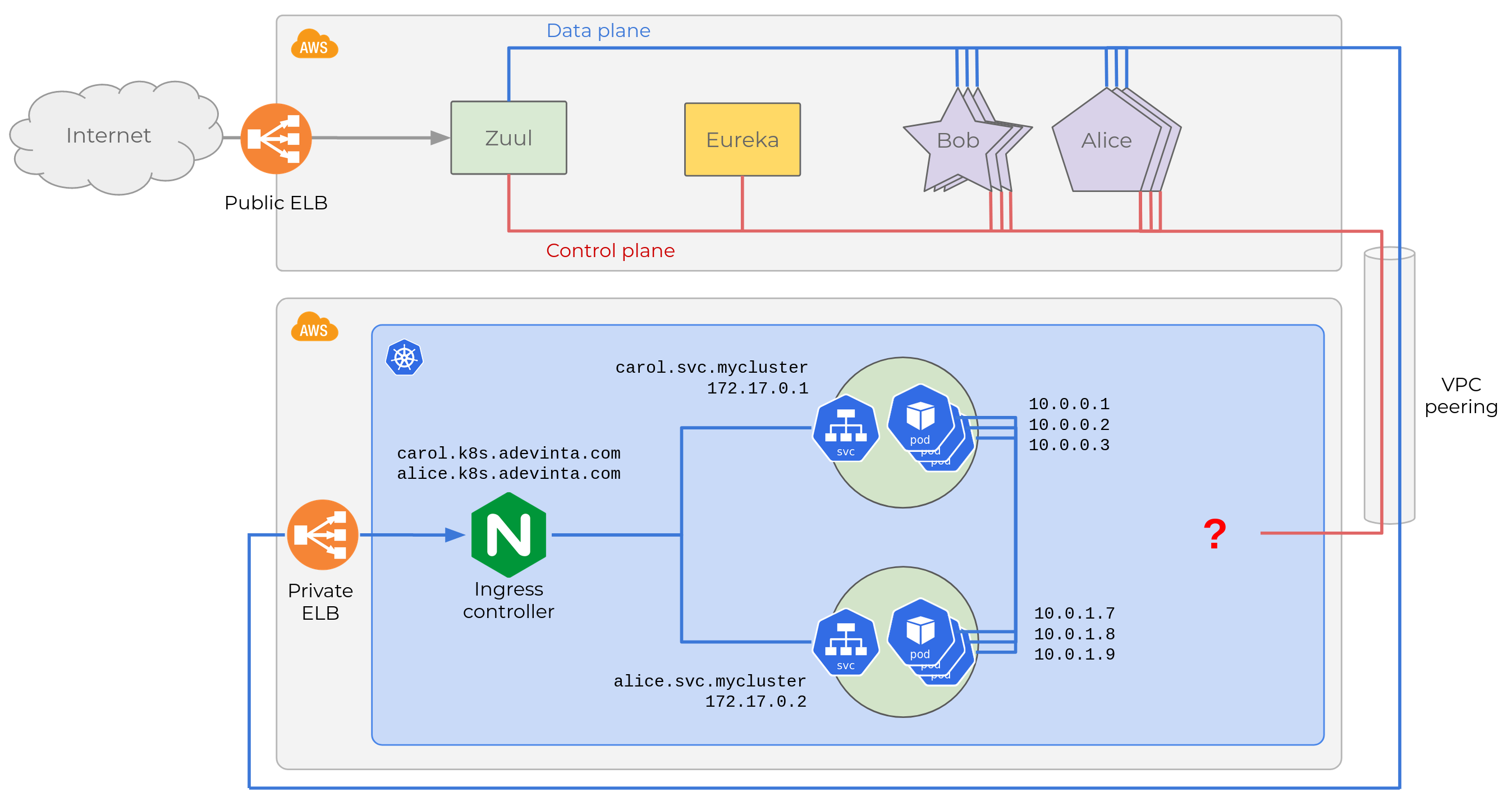 Adding the Ingress
Adding the Ingress
NGINX will map HTTP requests with a Host header
carol.k8s.adevinta.com to the service’s private DNS record,
carol.svc.mycluster, which resolves to the virtual IP, etc.
We give our tenants the choice of various Ingress classes depending on
whether they want their services reachable from the Internet, or through
a private ELB accessible only via VPC peerings. In this case, we’re
going for the latter as we want to keep all traffic among microservices
private, that’s why the Internet cloud is not connected to the ELB at
the bottom.
After creating an Ingress, the remaining challenge is making the
legacy control plane aware of the workloads running in Kubernetes.
Joining control planes
As noted before, every instance of our microservices should not register
their container IP, but use an address that hits the Ingress controller:
the private ELB’s IP. Let’s say it is 10.28.16.110, then Eureka’s
registry should look like this:
| Service | Instance ID | Endpoint | Port | … |
| Bob | Bob1 | 168.1.1.21 | 80 | … |
| Bob2 | 168.1.1.22 | 80 | … | |
| Bob3 | 168.1.1.23 | 80 | … | |
| Alice | Alice1 | 168.1.2.31 | 80 | … |
| Alice2 | 168.1.2.32 | 80 | … | |
| Alice3 | 168.1.2.33 | 80 | … | |
| Alice-k8s-1 | 10.28.16.110 | 80 | … | |
| Alice-k8s-2 | 10.28.16.110 | 80 | … | |
| Alice-k8s-3 | 10.28.16.110 | 80 | … | |
| Carol | Carol-k8s-1 | 10.28.16.110 | 80 | … |
| Carol-k8s-2 | 10.28.16.110 | 80 | … | |
| Carol-k8s-3 | 10.28.16.110 | 80 | … |
Each microservice now has an entry for its Pods. Notice how all have
the private ELB’s IP, 10.28.16.110. This is allowed in Eureka as long
as the instance IDs is different.
But this approach has downsides:
- We have to modify microservices so they report their own host’s or the ELB’s depending on where they are running. This is custom logic so it would need code changes.
- If our ELB changes IP (which happens sometimes), we have to propagate the change to every instance running in Kubernetes so they can in turn update their entries in Eureka.
To avoid them, we decided to follow a different approach. We built
Eurek8s, a Kubernetes
controller
that glues together the Control Plane in Kubernetes and the legacy
microservice platform of Adevinta Spain.
Eurek8s implements a simple control loop that propagates the state of each microservice to entries in Eureka. This gives us some benefits:
- We need no changes in microservices.
- We resolve the ELB’s IP dynamically in the controller before sending a heartbeat to Eureka. This way, changes in the ELB’s IP are propagated seamlessly.
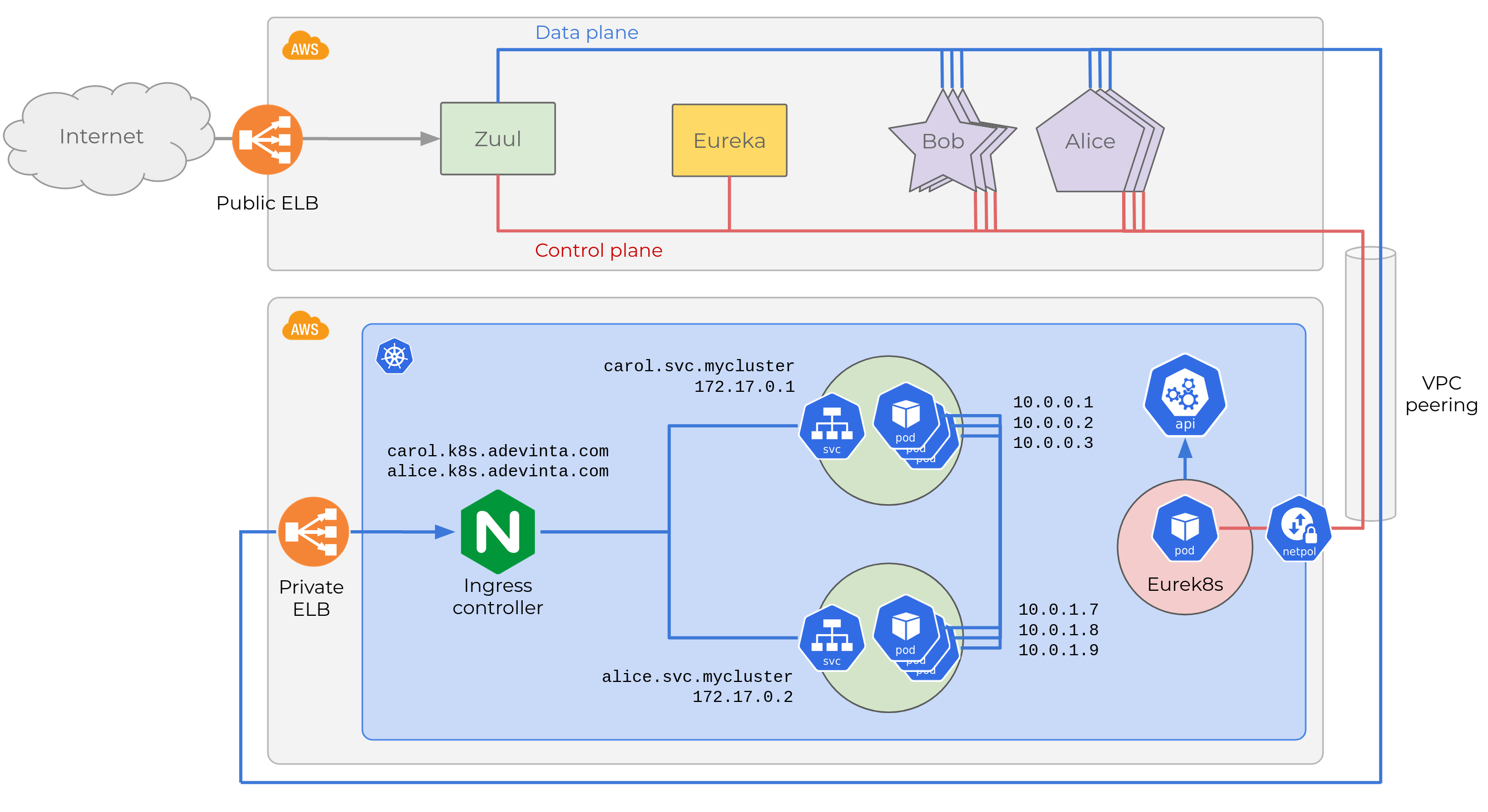 The full picture
The full picture
I’ll add a section at the end of this article with some implementation details of Eurek8s, but focus first on the main implications for our product engineers, and our plans moving forward.
Deprecating client-side load balancing
We realized that there was too much overhead in monitoring every
microservice’s Pod lifecycle events and their status to decide when
and how to register them in Eureka. Moreover, this would mean sneaking
through a backdoor into the abstractions why we came to Kubernetes in
the first place. What determines if our microservice is healthy or not
is a whole Deployment, we shouldn’t care about individual Pods.
Eventually, we decided to ignore the Pods and focus on the higher
level abstraction. Eurek8s registers only one endpoint per
microservice (a Deployment in practice), rather than one endpoint per
Pod. Therefore, based on the diagram above, Carol and Alice would
only have one endpoint regardless of the number of replicas:
| Service | Instance ID | Endpoint | Port | … |
| Bob | Bob1 | 168.1.1.21 | 80 | … |
| Bob2 | 168.1.1.22 | 80 | … | |
| Bob3 | 168.1.1.23 | 80 | … | |
| Alice | Alice1 | 168.1.2.31 | 80 | … |
| Alice2 | 168.1.2.32 | 80 | … | |
| Alice3 | 168.1.2.33 | 80 | … | |
| Alice-k8s | 10.28.16.110 | 80 | … | |
| Carol | Carol-k8s | 10.28.16.110 | 80 | … |
If you think this breaks client-side load balancing, you are quite right.
The microservices we migrate used originally a strategy that
round-robins requests evenly across instances. For example, when one
wants to talk to Alice, it would check the service registry table
(above), see 4 endpoints, and split traffic sending 1/4th of the traffic
to each one.
But Eurek8s is lying, it reports an endpoint , Alice-k8s, that
actually hides 3 replicas. In reality, each instance in EC2 would
receive 1/4th of the traffic while those in Kubernetes would receive
1/12th.
This was just not such a big issue for us. Why?
- Each service will run in both environments temporarily for just a few
days while the product team that owns it shifts traffic over from EC2
to Kubernetes checking that nothing breaks. This limits the time
where our load balancing is broken. As soon as 100% of the traffic is
going to Kubernetes, client-side load balancing is a NOOP, given there
will only be 1 endpoint per microservice, like in
Carol’s case above. - Moving forward, we are OK with Kubernetes taking over load balancing functions, the effort in keeping client-side load balancing working for a couple of weeks longer would not be well spent.
- Product teams can be made aware of this detail.
Outcome
After moving a few dozens of services, our assumptions worked out well. Because we did a major investment in automating most of the migration burden, it is indeed possible for engineers to get a service running in Kubernetes and start routing traffic there in just a few hours. Most services handle 100% of their traffic in Kubernetes in less than one week. Eurek8s has been quite stable so far, the focus on simplicity has surely helped making this possible. We discovered with minor edge cases discovered in the first batches of migrations that were easy to resolve.
The temporary Load Balancing distorsion has been harmless.
Future plans
Eurek8s will continue to enable the full migration of all workloads. By the time we’re done, both environments will look like this:
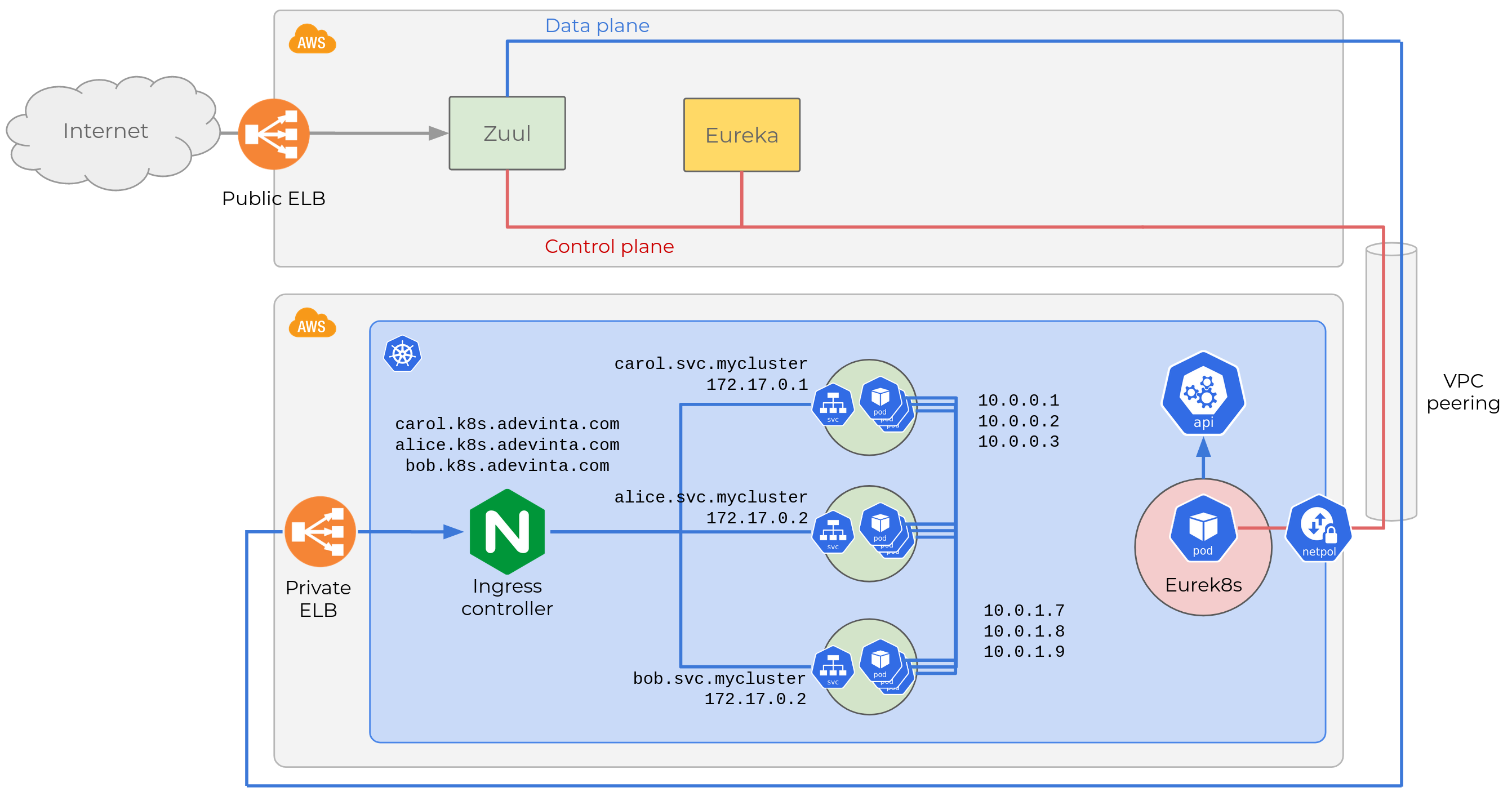 All microservices are migrated to Kubernetes
All microservices are migrated to Kubernetes
So Eureka registry will be quite boring:
| Service | Instance ID | Endpoint | Port | … |
| Bob | Bob-k8s | 10.28.16.110 | 80 | … |
| Alice | Alice-k8s | 10.28.16.110 | 80 | … |
| Carol | Carol-k8s | 10.28.16.110 | 80 | … |
Eureka will have become a dumb 1:1 mapping from service name to our
Ingress IP. At this point, removing it from our infrastructure will
be easy:
- For service-to-service communication, a trivial
change in each service
disables the Eureka client and replaces the endpoints of its
dependencies (e.g. from
bobtobob.svc.mycluster). We can automate this change making it transparent to product engineers. - On the API Gateway, Zuul, we can disable Eureka and configure the 1:1
mapping from the public host names to our internal ones (e.g.
bob.adevinta.comtobob.k8s.adevinta.com). - Decommission the Eureka server.
The fundamental change behind this process is to outsource Load Balancing and Service Registry to Kubernetes. This will initiate a larger conversation about the API Gateway.
Traditionally, API Gateways have been in charge of solving functions such as load balancing, TLS termination, header manipulation, dynamic traffic routing. After migrating to our PaaS, there is a significant scope overlap in the capabilities avaliable in Kubernetes and its ecosystem (e.g. from Ingress controllers, to service mesh solutions like Istio or Linkerd). We plan to spend some thinking time to define the split of responsibilities between the API Gateway and Kubernetes. This conversation is particularly relevant for other projects we’re working on, such as supporting transparent multi-cluster deploys that enable resiliency to full cluster failures, etc. Christian Posta has an interesting post on the role of API Gateways within the current industry landscape.
Eurek8s internals, for the curious
Finally, I’m adding an overview of how Eurek8s is implemented. Here is a high level diagram:
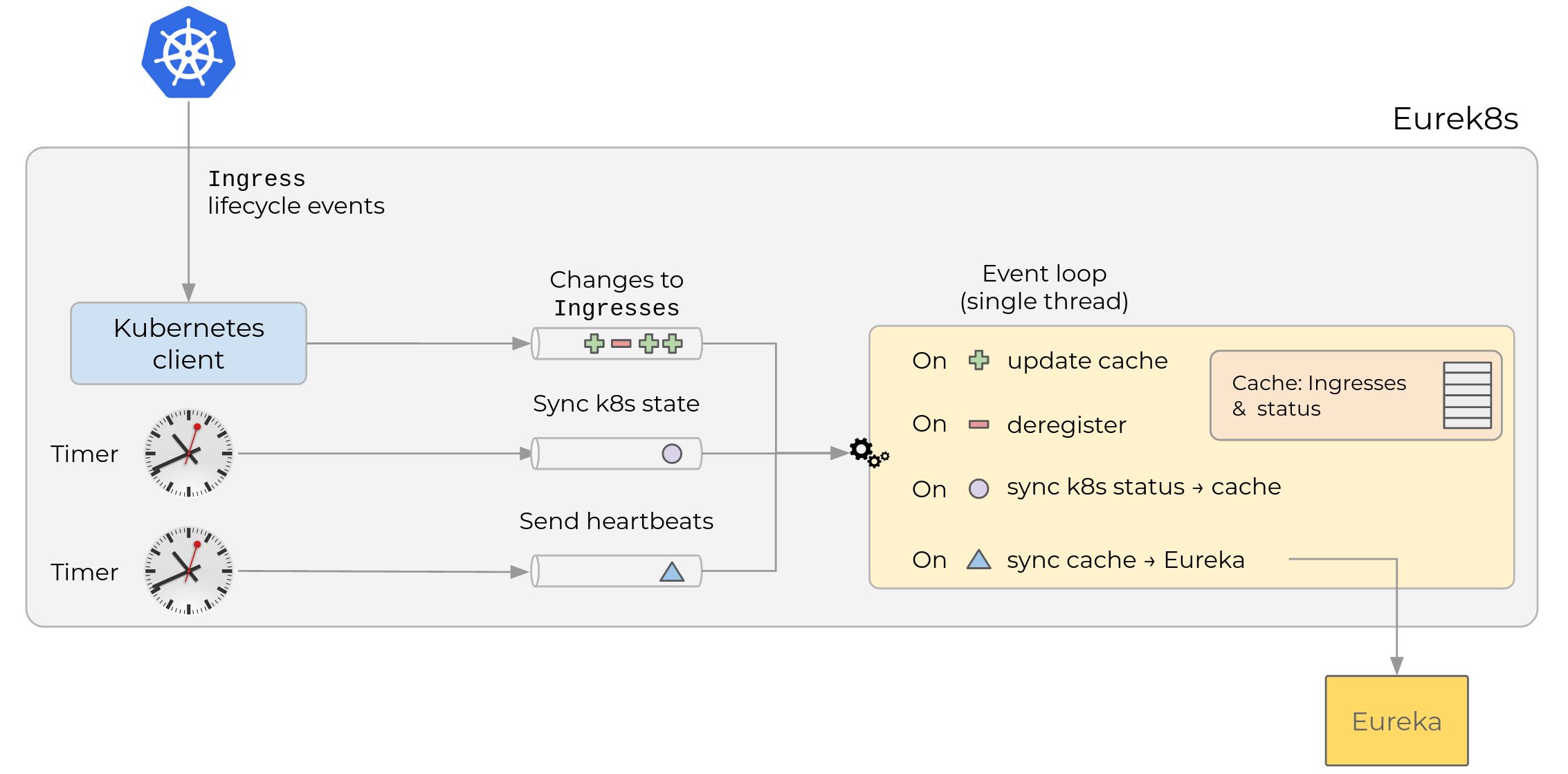 Eurek8s
Eurek8s
Eurek8s has three channels that are used to signal different types of events.
The first channel is fed from a Kubernetes
Informer,
that subscribes to changes in Ingress objects for a namespace with a
particular
annotation.
Depending on whether the Ingress was created/updated or deleted, a
message is sent in one or the other channel. Why listen on the
Ingress and not the Deployment? Conceptually it’s the same, we’re just
monitoring “a microservice”. We considered an Ingress preferable
because:
- We need the URL for the service to resolve the ELB’s IP. This URL
is configured in the
Ingressobject, so it’s cheaper to load it straight away, rather than listen to the deployment, and then load itsIngress. Ingressobjects are updated less frequently. But eachDeploymentchanges every deploy). Less notification churn reduces pressure on the Kubernetes API.
The other two channels are fed from timers that emit one message at set intervals. One signals when we should refresh the health status from Kubernetes. The other determines how often we send send heartbeats to Eureka.
All work is done by a single go routine, so we don’t need to coordinate access to shared datastructures. This is roughly how each message is handled:
- When an event appears in the “Created/Updated/Deleted Ingress” channel, the worker updates a local cache of Eureka entries, and immediately registers / updates / deregisters the entry in Eureka.
- When an event appears in the “Sync k8s status” channel, the worker
iterates through all known
Ingresses in the local cache, and updates the entry with the health of the relevantDeploymentobject in Kubernetes. - When an event appears in the “Send heartbeats” channel, the worker
does just that, for all known
Ingresses.
Both timed events at (2) and (3) involve multiple API calls to Kubernetes and Eureka so processing a single microservice can take ~250ms. With ~200s microservices, handling each sync / heartbeat loop would take ~50s. That is too much lag between state in Kubernetes and Eureka.
To reduce this time but keep the simplicity of a single-threaded
application, we just deploy Eurek8s per Kubenetes Namespace. This
achieves the same purpose (less Ingress objects to handle) and also
reduces the blast radius of one Eurek8s crash. This decision is easy to
reverse, using a single Eurek8s instance per cluster and splitting (2)
and (3) in separate Go routines.
Another decision was to run just one Eurek8s Pod per Namespace.
What’s the tradeoff?
- Replicating Eurek8s increases resiliency at the expense of complexity
coordinating instances so that replicas compete for ownership of a
subset of
Ingressobjects in their namespace. This is doable, but not trivial. - Having a single
Podimplies that losing it will stop all heartbeats. As a result, Eureka could deregister all instances from services in thatNamespace. This would be bad, but the risk in practise is quite low. First, if the Eurek8sPodcrashes, Kubernetes will spawn a new one, reducing the period of downtime to a few seconds (~5 in our tests.) This is actually so harmless that it happens every time we deploy a new version of Eurek8s. Heartbeats stop for ~5s and resume shortly after. Given that the endpoint timeout in Eureka is much higher (30s), such restarts are imperceptible. Again, this strategy is easy to reverse if necessary. Heartbeats are idempotent, so we can scale up to twoPodsanytime while we implement the coordination logic (at the expense of some load in Kubernetes and Eureka APIs.)
Testing Eurek8s
We have some basic unit tests, but given the nature of the tool we wanted an e2e testing suite that resembled production conditions. Kind has been beyond awesome for this purpose. If you haven’t heard about it, you should really check it out. It is a “tool for running local Kubernetes clusters using Docker container ‘nodes’. Kind was primarily designed for testing Kubernetes itself, but may be used for local development or CI.” It does the job beautifully.
We build a simple harness that uses Kind to create a local Kubernetes
cluster, we deploy a Eureka server inside it for convenience, along with
Eurek8s, and then implement a bunch of tests that mimic our production
use cases. The whole thing is quite lightweight and verifies our tool
in minutes.
Done
If you made it so far, thanks. This has grown definitely longer than I expected. Feel free to send me questions / corrections / feedback via Twitter, or the email you’ll find in my GitHub profile.
More writing
- DDoSing Software Delivery Pipelines Jun 2026
- Inferencing delivery bottlenecks away Mar 2026
- Code reviews can't keep up Feb 2026
- AI workloads challenge the cattle model Feb 2026
- PoC is a framework of perverse incentives Jan 2026
- AI-generated code will choke delivery pipelines Apr 2025
- See all →